Kenku FM Discord Derby
Kenku FM is our app that allows you to stream your music directly into a Discord call. In this post we're going to do a deep dive on how we greatly improved the streaming quality of the app.


How Kenku FM Works
Under the hood Kenku FM is a web browser. When you open your favorite website you're using the Chromium browser to load and interact with web content. We then provide a streaming layer that grabs the audio from the browser and sends it to Discord instead of your computer speakers.
Since the first version of Kenku FM there's been quite a few steps in this process. A lot of this comes from the structure of Kenku FM. The app is split into two halves; the first half runs the web browser and can interact with third-party content. The second half runs a NodeJS application that can interact with system level features of your computer. To ensure that no website you visit can harm your computer these two halves must remain separate. Since our audio engine needs to grab audio from your browser tabs it needs to run in the browser part of the app. But it also needs to send encrypted audio to Discord using a UDP connection which can only be done in the system level part of the app. So the audio engine needs to communicate and run across both contexts of the app.
Here's a graph of the steps the audio engine goes through to stream audio:
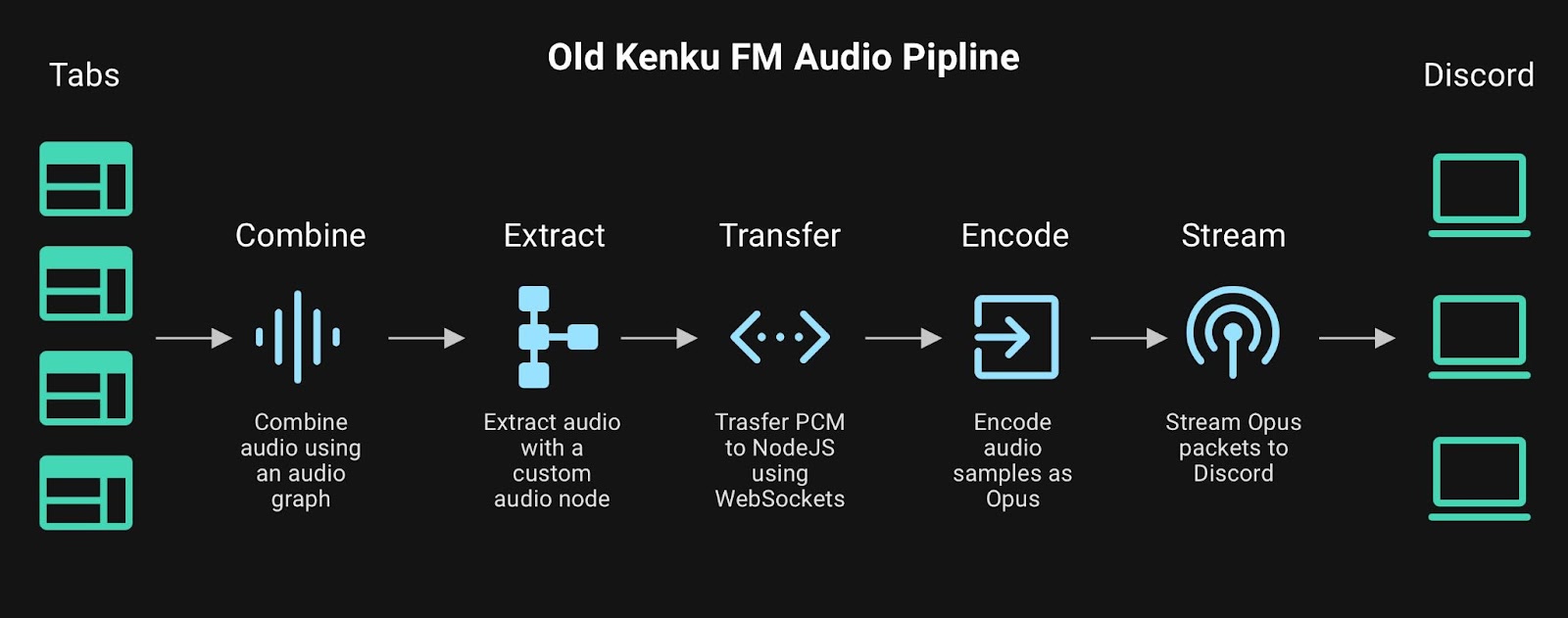
We first grab the audio from all your open tabs. We then mix that audio together using an audio graph. Extract the mixed audio into the raw audio samples. Transfer the audio over a WebSocket to the NodeJS part of the app. Encode the raw audio into a format that Discord expects and finally send that data to Discord.
Issues With This Approach
The approach listed above has a lot of steps, some of which are very inefficient.
Combining the tabs using an audio graph works well, we use the Web Audio API which allows the browser to handle the mixing of the audio in an efficient manner. To extract the audio out of the audio graph we use a custom audio processing node. This node sits at the very end of the graph where it is given the final mixed samples of all audio being played. All work done in the audio processing node must be very minimal because it has to process all the audio in realtime. So in order to send the audio from this node over WebSockets we buffer the incoming audio. We then steal audio samples from this buffer in a separate thread and send it over the socket.
This process adds latency because of the buffering. It also adds CPU overhead by using WebSockets for communication. On the NodeJS side we need to encode our audio into the Opus format until we can finally send the audio to Discord. To do this we use a WebAssembly module which is fast but not as fast as doing the encoding using a lower level language.
All in all this pipeline has a few inefficiencies that have always bothered me. So over the last few weeks Nicola and I finally set out to clean up this process in a hope to reduce latency and increase the quality of the audio. Especially in CPU constrained environments.
Solution
Web browsers already have an audio streaming technology built into them called WebRTC. It's built for streaming so it has minimal latency. It works over a UDP connection so it will be more efficient then WebSockets. It also supports Opus encoding out of the box so we wouldn't need to run a separate encoding step.
With WebRTC our new audio pipeline would look like this:
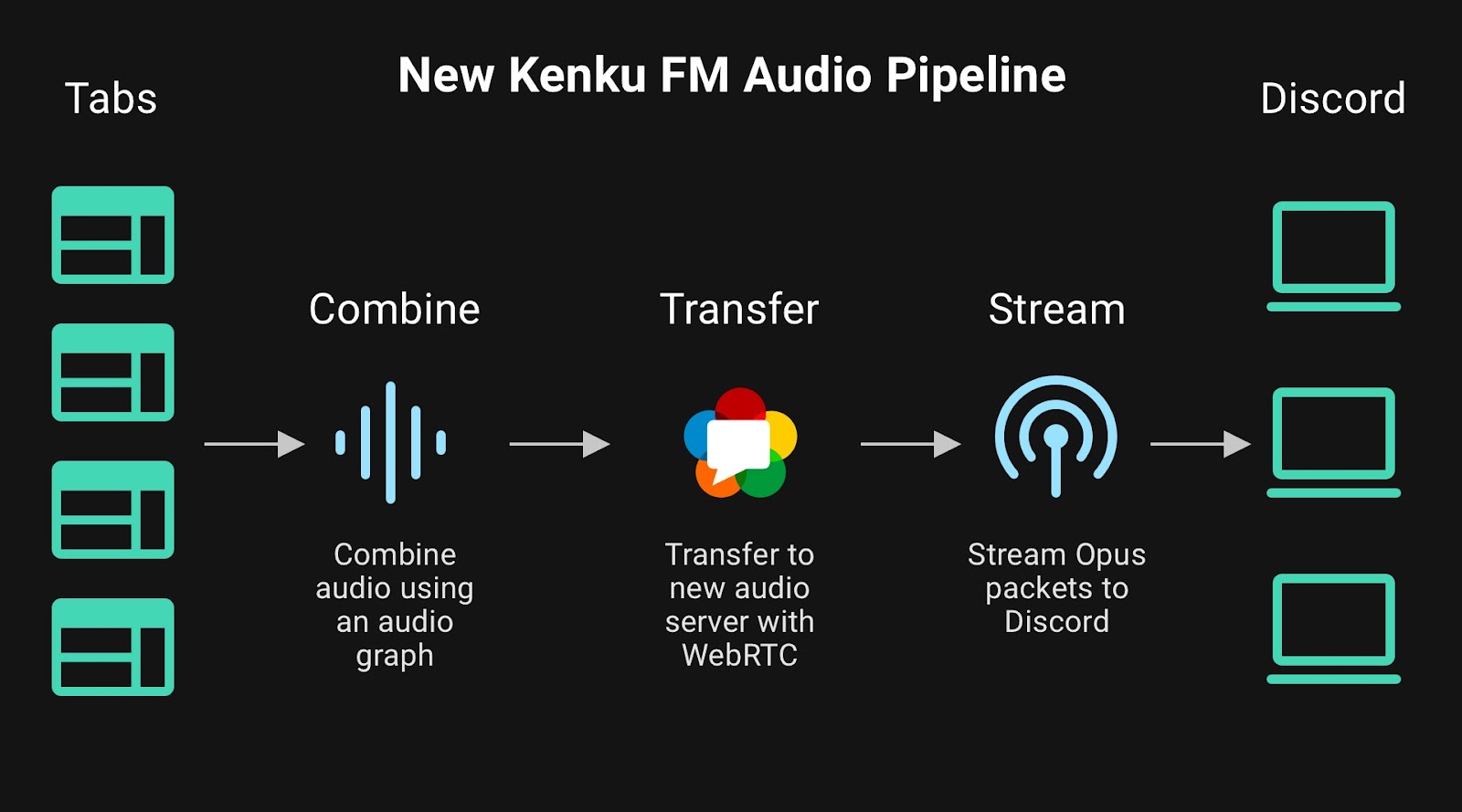
This is a lot simpler so why didn't we do this in the first place? Because our app uses Electron the main context of our app is written using NodeJS. NodeJS has a popular WebRTC library but it doesn't support ARM architectures. This won't work for us because we ship ARM versions of Kenku FM for Linux and MacOS. To get around this limitation we had to look to other programming languages.
We found that Go and Rust both have robust WebRTC libraries which work across all platforms. However, now we need to find out which language would work better for us. In order to test this we created a WebRTC/Discord Derby. We implemented our audio pipeline in both languages and pitted them head to head to see which would be better for Kenku FM.
Comparison
Rust is a lower level programming language generally used for high performance applications. Go is a language that is used a lot for web servers as it works very nicely with asynchronous code. Go uses a garbage collector to clean up memory whereas Rust uses a static borrow checker to enforce strict memory requirements. This strictness means programs can be more complicated to write in Rust but it removes the uncertainty that comes with garbage collection. Nicola (who handles the servers in Owlbear Rodeo) had used Go before so she was the main driving force behind the Go implementation. While I had never used either language before this update so I tackled most of the Rust version.
We like giving projects names when we work on them so we called the Go app Disgo and the rust app Severus.
Disgo was an order of magnitude easier to write. I think this comes down to the fact that we were essentially building a WebRTC broadcast server which fits very well into the strong suits of Go as a language. The Rust app however, was easier to integrate into Electron. Specifically using the Neon library which allows you to compile your Rust code into a NodeJS compatible binary.
A large roadblock we faced on both platforms was actually the community Discord libraries provided. Both Go and Rust have popular libraries that make it easy to communicate with Discord which are great. Unfortunately they aren't set up to easily account for our streaming nature. In the short term we created forks of the libraries we needed but as we work more on this we'll most likely create a more tailored library for our use case.
WebRTC Glitches
When we first implemented the new WebRTC streaming server both the Go and Rust version had an audio skip every 5 seconds. It was small and only lasted a brief second but it was very annoying. To find out what caused this we dug into one of my favorite screens of Chromium based browsers `chrome://tracing`. The Chrome tracing tool allows you to profile various internals of the browser and see what's happening under the hood.
We ran a trace and went looking for calls to the WebRTC network. Here's a recording of a regular WebRTC event:
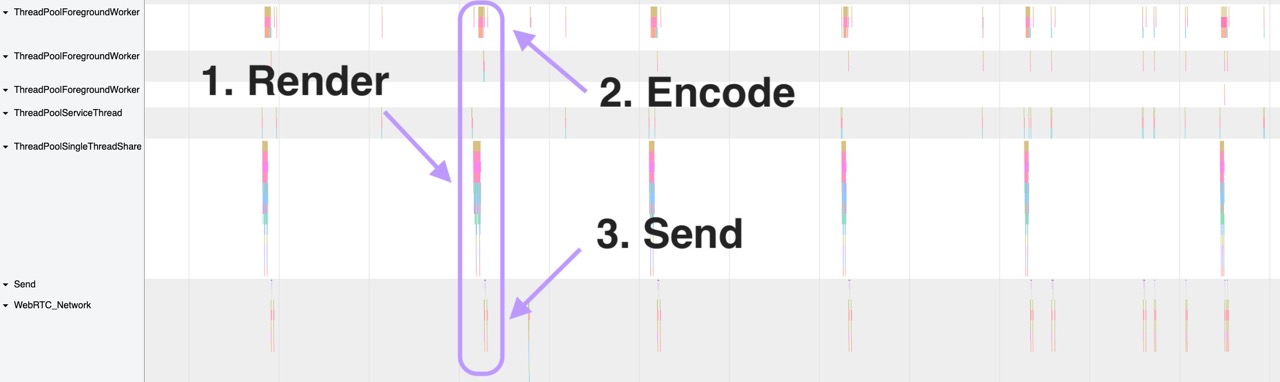
First the audio is rendered, it is then encoded into Opus and then it is sent over a UDP connection. This happens every 20ms which is what we were expecting. What we weren't expecting was what happens at the very end of the WebRTC network trace. Specifically with the four very quick succession network requests being made:
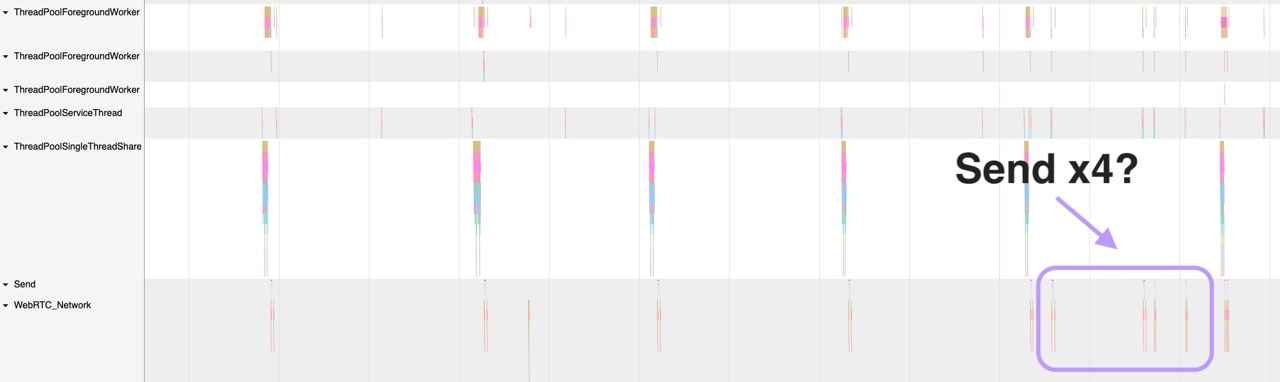
When looking at the packet length of these requests it looks like they only include headers because they're very small. So we think they may be some sort of heartbeat mechanism or perhaps some sort of error correction. Either way the payload of these packets were empty so in our server we knew we could safely ignore them. After we did this the audio glitching went away and we haven't noticed any downsides yet. If you're reading this and know what these packets do I'd love to know.
Results
In order to get real world results we used a Windows 10 computer with an Intel Core i5-6500 CPU and an RTX 3060 TI GPU. We chose a popular but older CPU here to better represent a wider range of systems. To further test a real world scenario we ran video encoding (to simulate a video call). We also ran an artificial CPU stress test to simulate other CPU intensive programs running (like a VTT).
Here are the results playing back a song from Tabletop Audio. We compare the previous version of Kenku FM versus the new Disgo and Severus audio pipelines. As the test progresses we artificially increase the CPU load to 50 and 75%.
All versions offer clean playback when given full CPU resources. At 50% CPU load the previous version starts to exhibit audio stutters every few seconds. While at the same load Disgo shows less frequent stutter and Severus is stutter free. At 75% CPU load the previous version stutters very frequently to a point where it would be unusable. Disgo holds up well only exhibiting a couple of brief stutters while at this 75% value Severus shows its first few stutters as well.
With very limited stutters at 50% CPU stress the new Severus pipeline seems to offer the cleanest playback. While the Rust code does complicate the codebase a bit we're hoping that the reduced latency and added stability will more than make up for it.
Severus will be deployed with version 1.3 of Kenku FM so feel free to download it and give it a try.